Flink性能调优之序列化与反序列化
在Flink中序列化和反序列化是影响性能的一个重要因素。不合适的序列化器的使用以及过多的序列化反序列化操作都可能极大地影响性能。就我个人的经验来说,去除代码中多余的序列化操作使得吞吐量从2万提升到了8万。
本篇博文主要围绕以下内容展开:
- 什么是序列化和反序列化?它通常用于什么地方?为什么序列化反序列化会较大地影响性能?
- 在Flink中哪些地方会用到序列化和反序列化?
- 针对序列化和反序列化的问题,该如何做性能优化?
序列化和反序列化的基本概念
序列化和反序列化
序列化: 将数据结构或对象转化为二进制串的过程
反序列化:将在序列化过程中所生成的二进制串转化为数据结构或者对象的过程。
对于java语言,二进制串指的是byte[]。因此在java中,把对象(如class 实例,String,Tuple等)转化为byte[]的过程就叫做序列化,反之就叫做反序列化。
为什么要进行序列化?一是为了数据持久化存储,二是为了数据网络传输。 都需要把不同语言特有的对象转化为通用的字节流。
序列化格式
我们以怎样的格式(协议)将对象转化为二进制串呢?序列化格式主要分为两类:文本格式和二进制格式。文本格式是把对象视为文本,按照字符编码的方式处理;而二进制格式则是将对象按照其在内存中的存储形式处理。两种格式只是对象转化为二进制串的方式不同,最终保存的都是二进制串。
举例来说
1 | |
json序列化(文本格式)的结果是:’{a:1,b:2} ‘是根据字符编码序列化为文本形式。而bson(二进制格式)则是内存中的数据按其在内存中的存储形式原样取出即可。
常见的序列化格式:xml,json,ProtoBuf,Thrift,MessagePack
文本格式的序列化可以将对象写出字符串,二进制格式的则不能。
序列化工具
常见的Java序列化工具:
- Binary Formats & language-specific ones
JavaBuiltIn(java原生)、JavaManual(根据成员变量类型,手工写)、FstSerliazation、Kryo - Binary formats-generic language-unspecific ones
Protobuf(Google)、Thrift(Facebook)、 AvroGeneric、Hessian - JSON Format
Jackson、Gson、FastJSON - JSON-like:
CKS (textual JSON-like format)、BSON(JSON-like format with extended datatypes)、JacksonBson、MongoDB - XML-based formats
XmlXStream
序列化和性能的关系
不同的序列化格式,不同的序列化工具对性能都有影响。这一块我没有深入研究。
但就我使用的Jackson而言,它的序列化和反序列化使用了java的反射机制,导致性能不高。
Flink中序列化和反序列化
上面提到了序列化和反序列化的用途就是数据传输和持久化存储。就一个Flink job而言,涉及到序列化和反序列化的也就是这两个场景。下面来细看。
序列化和反序列化场景
数据传输
- 进程间: 有
如果不同的子任务处于不同的进程(taskmanager),数据需要经过网络传输,需要进行序列化和反序列化; - 同一个进程不同线程间: 有(通常的多线程是内存共享的,但flink不一定)
如果是同一个taskManager的不同线程的发送任务和接收任务,接收任务会将数据从字节缓冲区的数据拉取过来而不涉及网络通信开销,数据序列化后会先通过recordwriter,然后通过local channel发送给另一个task的input gate,然后反序列化,再交给recorder reader进行处理。 注意:线程间情况下,不管任务是不是在同一个slot上运行,数据传输都会进行序列化操作 - 同一个线程
通过传参的方式对象传输,不涉及序列化和通信;默认没有对象复3用,即深拷贝;开启对象复用后,为浅拷贝。
持久化存储
- rocketDB中状态读写,如果是Heap作为stateBackend,则状态的读写不涉及序列化和反序列化。
- checkpoint和savepoint的存取;
Flink的序列化器


注意: 采用第三方的序列化器需要采用对应的数据类型。
各种序列化器性能的比较
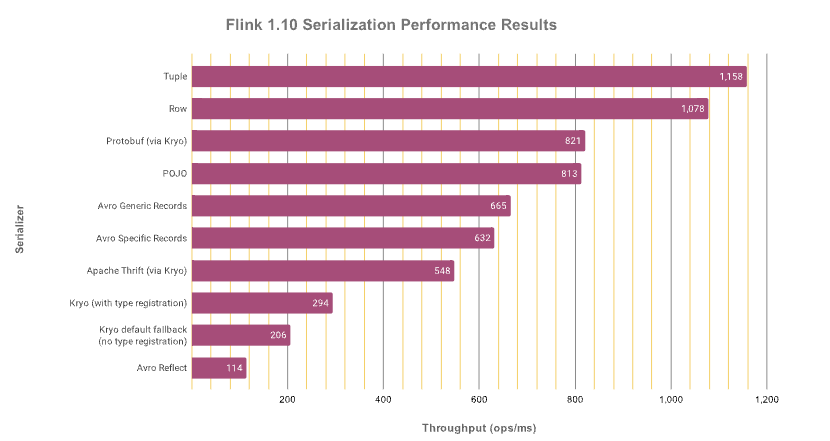
The fastest de/serialization is achieved with Flink’s internal tuple and row serializers which can access these types’ fields directly without going via reflection. With roughly 30% decreased throughput as compared to tuples, Protobuf and POJO types do not perform too badly on their own and are more flexible and maintainable. Avro (specific and generic) records as well as Thrift data types further reduce performance by 20% and 30%, respectively. You definitely want to avoid Kryo as that reduces throughput further by around 50% and more!
序列化方案对吞吐量有很大的影响!!!
解决方案:
If you cannot use POJOs, try to define your data type with one of the serialization frameworks that generate specific code for it: Protobuf, Avro, Thrift (in that order, performance-wise).
调优方法
- 减少不必要的序列化和反序列化。比如将可以合并的算子合并为算子链。
- 选择合适的数据类型以及序列化工具。这一块有机会再深入研究。