Flink维表关联方案
数据流往往需要访问外部的数据源来丰富自己的信息,比如通过record中的ip地址查询ip数据库maxmind的GeoIP2 Databases得到ip对应的城市名称,城市经纬度,将这些作为新的字段添加到原来的record中。这就涉及到本篇的主题:维表关联。
网上关于flink中维表关联的博文很多,本文我想谈一谈个人对不同方案的理解和尝试后发现的一些问题。如果想要比较全面地了解维表关联的各个解决方案,建议阅读参考文献前两篇。
技术选型
维表关联方案主要有以下几种
- 实时数据库查找关联,又叫热存储维表
- 预加载维表关联
- 广播维表关联
- 维表变更日志关联,最常见的就是Temporal table function join
这几种方案各有优劣,没有最好的方案,只有最适合的方案。
所谓实时数据库查找就是Flink中的算子保持与数据库的连接,每来一条record就提取关键字,直接查找外部的数据库。这个方案最致命的问题在于这种实时访问外部数据库进行查询的方式是很影响作业性能的,对数据库的负载很大,导致吞吐量很难提上去。而且大数据的流量一般都很大,频繁访问数据库导致产线上的数据库挂掉那就是重大的生产故障。当然,针对这个问题也有一些解决方案,比如同步查找可以替换为异步查找,还可以使用缓存使得热点数据直接在内存中就能找到不用访问外部数据库。Anyway,带来的性能提升效果有限,这种方案主要还是适用于流量不大的场景。
预加载维表关联就是在任务启动的时候就把维表加载在内存中,查找的时候直接在内存中找就可以了。这个方案查找的性能是最高的,毕竟直接在内存中查找。但它也有一些局限性,一是占用更多的内存资源,如果维表非常大(比如大于TM内存),就不可取;二是维表很难实时更新,尽管可以设置定时器定时刷新维表,但是如果维表更新的太频繁性能消耗就太大了。总的来说,这种方案适合维表不是非常大,维表更新也不是很频繁的场景。(该方案实现简单,性能高,也是我最终选择的方案)
前面两种方案都属于数据流与静态的表之间的关联,而后面两种方案则是数据流与数据流之间的关联。所谓广播维表就是将维表转化为广播流从Source广播到下游的算子中,然后作为广播态保存到State Backend中,可以是内存,也可以是rocksdb。将广播态保存到rocksdb中每次读取状态都涉及到序列化和反序列化,对性能是有一定影响的。将广播态以MapState的形式保存在heap中和预加载维表关联就比较类似。
我这边将预加载维表关联和广播维表这两个方案做一个对比:
- 都可以将完整的维表保存在内存中,维表查询性能较高。但是广播维表需要将维表从上游广播到下游,涉及到不同节点的数据传输(网络传输,序列化和反序列化等),会带来额外的性能损失。但是作为广播态保存,不同的slots可以共享广播态,每个TM只需要保存一份维表,而不是每个slots保存一份,内存的利用率更高。
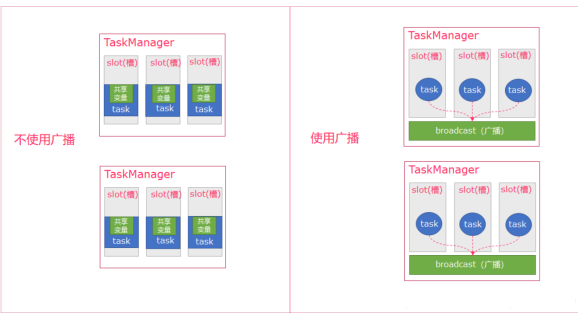
- 广播维表需要把维表转化为数据流。好处是维表的实时性更高,方便实时更新。不好的地方是通常是把维表存储在Kafka中,考虑到实时性,实现上更复杂。也可以自定义source定时把最新的维表转化为数据流,和预加载维表的定时刷新方案一样,但这样维表更新就有延迟。
- 维表广播只能是数据流和一条广播流的join,不可以数据流和多条广播流join。预加载维表方案同一个算子可以预加载多个维表,维表广播的方案就需要把多个维表转化为同一个数据流进行广播,然后保存在不同名字的广播态中。实现起来比较复杂,另外就是代码聚合程度太高,很不优雅。
总的来说,广播维表方案维表的实时性高,数据查询性能高,资源利用率也高,属于比较全面的一个方案。缺点主要在于实现上较为复杂,而且也要求维表不能太大。
最后提一下维表变更日志关联,主要是Temporal table function join。目前Datastream API不支持,需要写Table API/Sql。这一块我没有做太多研究,就此不表。
代码示例
实时查询外部数据库
使用cache来减轻访问压力
1 | |
使用异步IO来提高访问吞吐量
1 | |
预加载维表+定时刷新
我的维表是以文件的形式保存在本地磁盘中的。
如果是保存在外部数据库可参考参考文献4
1 | |
广播态
1 | |